


I am an independent AWS consultant providing services through my company 1way2cloud GmbH. If you would like to engage me on your project, feel free to contact me directly at nemanja@1way2cloud.com.
To quote Elon Musk “Prototypes are a piece of cake, but going to production is extremely hard.“
The same quote would apply to developing applications in the cloud. Assembling a few services together through a management console is not a big deal. The problems start when you get serious about using that application in the production, with real users and real data. This is point when you wish you had automated your application to the maximum.
Why is automation that important?
Humans make errors. Machines don’t. Or at least if a machine does make an error it forms a repeatable pattern, easier to diagnose and typically introduced by the aforementioned human. If you can keep a human out of the picture, you can have a confidence that things will run as intended. Automation brings speed, accuracy, reliability and repeatability. (Tesla’s Gigafactories are good example of how important production automation is)
In the cloud, automation is achieved by using infrastructure as code for the application environment creation and by using CI/CD pipelines for deploying code into those environments. Looking specifically at AWS cloud, a tool of choice for infrastructure as code management would be AWS CDK (Cloud Development Kit). In this post, we will explore how to use AWS CDK to structure an application so that different teams can work on different items but still be synchronized. We will especially take a look at a particular problem with using multiple AWS CDK stacks which is – passing parameters between the stacks.
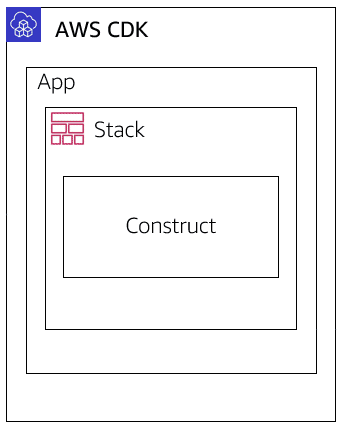
Note: assumption here is that readers are familiar with the AWS CDK framework. We won’t describe details about it, but will focus on specific issue of cross-stack and cross-app resource references. If you want to learn more about AWS CDK, take a look at a newly released and free digital training “AWS Cloud Development Kit Primer”. Just for a terminology sake, we will be using AWS CDK Application term for one complete CDK project. Each AWS CDK application can have one or more Stacks inside and each Stack can have one or more Constructs.
Let’s take a look at a real world application and use it as an example to demonstrate usage of AWS CDK framework. It is a serverless application that I am currently working on – an automated trading bot that is trading several different cryptocurrencies over a few exchanges.
The structure of such application is as following picture shows. Nothing unusual, few components that are capturing different application layers.
App Logic is the brain of the application that is handling operations such fetching market tickers, analyzing price movements and, based on the trading algorithm, decides to place buy or sell orders, or to cancel existing orders in case the market starts behaving abnormally. The current information needed for the price analyzing is stored in AWS DynamoDB database and all historical ticker data are stored in Amazon Timestream database. We use Amazon QuickSight to visualize trading data from the Amazon Timestream database. All the logic is defined in AWS Lambda functions that are using asynchronous messaging (over Amazon SQS fifo queues) to communicate to each other. Amazon EventBridge service is used to trigger the whole process every minute.
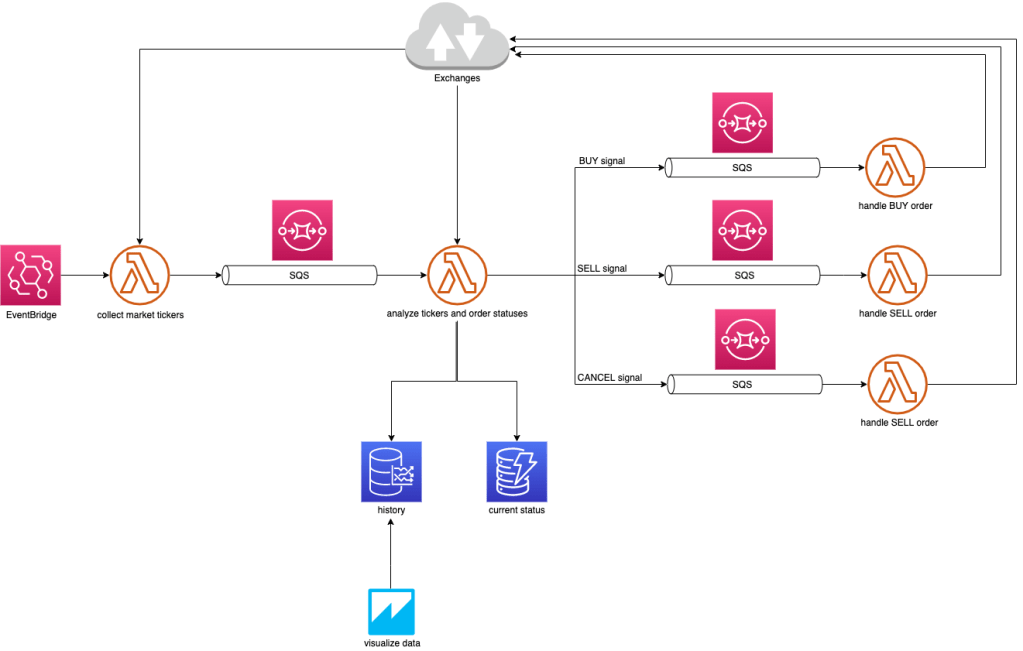
App UI is an application interface that allows interaction between users and the application logic. In our case it is a simple mobile application that fetches data from the back-end over Amazon API Gateway and AWS Lambda. It can also halt the whole trading if needed by disabling Amazon EventBridge rules.

Once the environment is created, the only development that happens is in AWS Lambda functions. Therefore we need to create CI/CD pipelines for every AWS Lambda function that is being used. The same deployment pattern is used for each AWS Lambda function:
- AWS CodeCommit is a source code repository
- on each “git push” to AWS CodeCommit, an AWS CodePipeline is triggering the next stage in the deployment process, which is AWS CodeBuild, that takes the source code, builds it and prepares AWS CloudFormation script.
- finally, AWS CodePipeline triggers update of AWS Lambda functions by executing AWS CloudFormation change set.

Now that we have seen how the overall application looks like, let’s see how we can model these AWS services in AWS CDK applications to automate deployment of the application in AWS.
The simplest approach that comes to mind is – put it all in one AWS CDK application.
That would work and most of examples in the AWS documentation and other blog post are structured that way. But for any kind of larger development, such approach is too simplistic. Companies have different teams with different skill sets. Each team is responsible for the part they understand the best. Infrastructure teams are maintaining underlying infrastructure services that are used by developers to deploy application on top of. Ops teams are making sure deployment pipelines are functioning well and that monitoring tools are in place. Developers are focusing on implementing business requirements, without needing to worry about infrastructure or deployment pipelines.
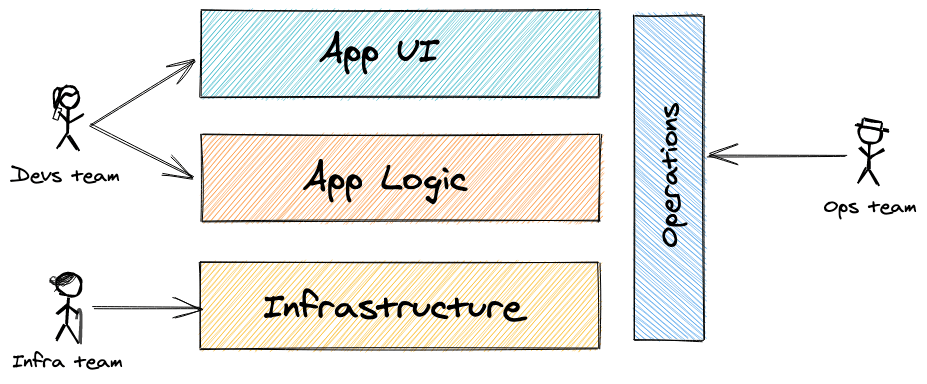
With AWS CDK, we would want to mimic this kind of structure so that segregation of duties is still maintained. We would have three separate AWS CDK applications:

Let’s take a deeper look at each of these AWS CDK applications.
Infra CDK
In the infrastructure CDK we will place all services that are needed to create our working environment. These are the services that don’t need to be changed often. Remember, the main development activities are in AWS Lambda functions that are taken care of other teams. Here we are looking at services that infrastructure team is responsible for. These are services that are used by higher application level services (such as AWS Lambda).

When creating infrastructure CDK application, we would execute “cdk init –language typescript” only once. Every new service we want to add in this stack, would be added as a single stack under the /lib folder. In our case, we have one folder per service inside the /lib folder like this:

As you can see, we are using AWS CDK Stacks to compose our infrastructure layer. We are defining one stack per each service under the /lib folder of our Infrastructure CDK. Let’s take a look at one of those stacks, let’s say timestream-stack.ts in /lib/timestream folder:

Again, nothing unusual here. A standard way of defining constructs inside a stack.
Where it all comes together is in infrastructure.ts file in the /bin folder where we reference all those stacks and link them up with the main CDK Application construct, like this:

Deploying the full infrastructure CDK application is as simple as: “cdk deploy -all”
DevOps CDK
Similarly to the previous Infra CDK, in the DevOps CDK application we would put all the AWS services that are used for deploying source code through the pipelines. Per each AWS Lambda function we would create such a stack. In a true microservice fashion, each AWS Lambda would have its own source code repository and its own pipeline created with AWS CodePipeline service. DevOps teams in your company would be the one maintaining this CDK application.

Apps CDK
This one is dedicated to defining AWS Lambda functions. As we mentioned previously, AWS Lambda functions are used to implement both our business logic (App Logic layer) and REST API’s used by the mobile front-end application (App UI layer). Previously defined DevOps CDK will be creating CI/CD pipelines for each of these individual AWS Lambda functions.


Putting it all together
Now that we have 3 separate AWS CDK applications, one per each layer, we can just execute “cdk deploy –all” for each of those applications and the whole environment would be created for us in AWS.
That is great, because now we can create as many environments as we want. We can create Dev, Test, Prod accounts for each of our customers and execute CDK scripts in each of those accounts. Within minutes, we would have a fully functional environment.
But… there is one issue that you might notice when working with multiple CDK stacks and applications. That would be: passing parameters between stacks inside the same CDK application and passing parameters between different CDK applications.
In the next Fig 14 we see both problem statements. Passing parameters between stacks inside Infrastructure CDK application and passing parameters from the Infrastructure CDK application to DevOps CDK and Apps CDK applications.

Let’s see in our application where can we expect such parameters passing between stacks within the same CDK application and between different CDK applications:
- Passing parameters between stacks within the same CDK application:
We have SQS CDK stack and IAM CDK stack in our Infrastructure CDK application. Inside IAM CDK stack we are defining IAM roles for Lambda. One of those roles has a policy that allows Lambda to send messages to an SQS queue. To define that policy, we need specify resource that is affected by the policy. In the Fig 15 below we see that in the IAM CDK stack we are using “sqs.queueArn” to reference the SQS queue. So, we need somehow to pass SQS ARN (Amazon Resource Name) from SQS CDK stack to IAM CDK stack.

- Passing parameters between separate CDK applications:
The similar issue we have when passing SQS ARN from SQS CDK stack (defined in Infrastructure CDK application) to a Lambda CDK stack (defined in Apps CDK application).

So, how do we solve this? There are several ways.
- Manual rewriting
You can always start the Infrastructure CDK application first and wait for it to be finished. Then you can copy all the ARN’s and other created resources that you need and manually paste them into other CDK applications that will be executed afterwards.
It’s not so great approach in the spirit of automation but if the CDK applications and stacks are not huge and not executed often, it can be a valid approach.
- Command line parameters
You can always pass parameters to CDK during the deployment execution, like this:
cdk deploy IAMStack –parameters SQSARN=”arn:aws:sqs:eu-west-1:27263352:TicketQueue.fifo”
Here we are deploying IAMStack and passing SQSARN as a parameter.
Inside IAMStack, we can reference that parameter by using CfnParameter construct:

This approach is better than Manual rewriting as we are not modifying stacks but just passing
parameters to them. This approach doesn’t require executing usual set of commands
(npm run build, followed by cdk synth) that are necessary after each stack modification.
- One CDK application and one stack
You can avoid all the problems with passing parameters if you define all your constructs inside a single CDK stack within a single CDK application. Constructs are then in the same scope and can easily reference each other.
For smaller projects where there is one team managing end-to-end delivery (infrastructure, operations and development) it makes sense to use a single stack and place your constructs inside it.
- CDK Stack properties
Here we will show how to pass parameters (that SQS ARN from the example above, Fig. 15) from SQS Stack to IAM stack.
Parameters are passed within infrastructure.ts file in /bin folder, that is where CDK App is initialized. The following code snippet shows how we are passing 4 SQS queues from SQS stack to IAM stack:

To make those SQS queues visible on the App level, we need to declare them as public variables in the SQS Stack file:

Then we modify IAM Stack file to include new interface that extends StackProps core construct. From there, we can reference properties within the IAM Stack code.

- Value Import/Export
The previous way of passing parameters will work for stacks that belong to the same CDK application (Fig 15). But it won’t work for passing parameters when stacks are defined in separate CDK applications (Fig 16).
For cross-application reference we need to rely on low-level CloudFormation constructs CfnOutput and Fn.importValue.
In SQS CDK stack we would put queue ARN in CloudFormation outputs:

To verify that the value is really visible, you can open CloudFormation in AWS Management Console,
and in Outputs tab see the value under the export name we defined:

Now we just need to import that value into IAM Stack. We do that by using Fn.importValue
function.

This approach solves our cross-application reference issue. It is worth mentioning that it only works
within the same AWS account and the same region.
- AWS SSM Parameter Store
Values between any two stacks (within the same CDK application or between separate CDK applications) can be exchanged via AWS SSM Parameter Store.
In SQS Stack, we would write ARN value as a string parameter in SSM:

Then any other stack can read it from there:

With that, we are wrapping up all the options there are to pass parameters around. If you managed to stick around until this point, kudos to you. 🙂 As a bonus point, here are some tips I think might be useful for you when working with CDK.
Few general CDK tips
- npm version dependency
AWS CDK is written in Typescript. It supports other languages as well (Python, C#, Java) but the CDK code is compiled into those languages with the help of JSii tool. Because of usage of Typescript, CDK is using Node Package Manager to install new modules. When you need a new CDK construct, you would install a new npm module, like this in case you need to use S3 constructs: npm install @aws-cdk/aws-s3. As those modules are developed independently by the open source community, the versions of modules are not aligned and quite often there is an incompatibility between module versions.
By using command npm outdated you can get a list of modules that are installed and their versions.

We see here that our current version of modules is 1.83.0. Our CDK core (aws-cdk) is also version 1.83.0. If I would now need to install, let’s say AWS SAM CDK module, I would use:
npm install @aws-cdk/aws-sam
But, be aware that this way we would get the latest SAM module, which is 1.85.0. This version might not work with our core 1.83.0 version. That is why I would recommend always to use specific version when installing modules:
npm install @aws-cdk/aws-sam@1.83.0
Another way is to update all modules to the latest version with npm update.
- CDK Construct levels
When working with AWS CDK you will read in documentation or in different blog posts something like “CDK L2 construct”. CDK has three levels of constructs, like this picture shows:

You will mostly be working with L2 and L1 constructs. L3 constructs are “opinionated” constructs created by different AWS Solutions Architects that might or might not meet your needs.
- Values at synthesis and deployment time
It is useful to know the lifecycle of a CDK application. During deployment of a CDK application there are two phases that sometimes can confuse developers: synthesis and deployment phase.
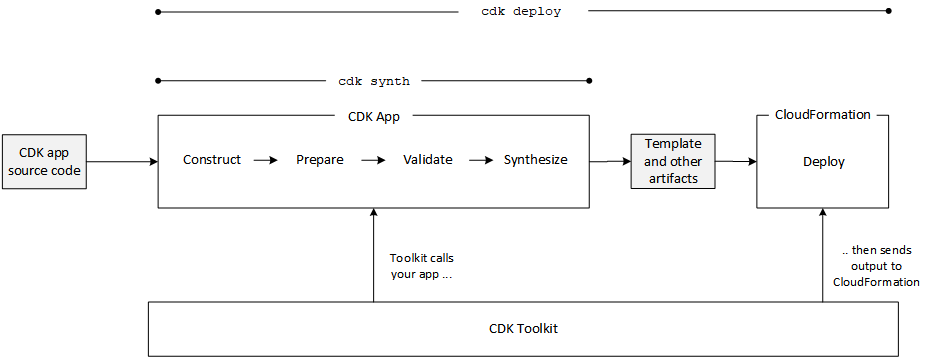
As a consequence of that, you might be wondering why you “don’t see” some resources during the synthesis time. For example, if your CDK application defines an S3 Bucket with an automatically generated name, that name will only be known after it has been deployed. The value of the bucketName attribute will be a symbolic value, looking something like "${TOKEN[Bucket.Name.1234]}" at the synthesis time. You can pass this value to constructs, or append it to other strings, and the CDK framework will make sure to translate these values to the right pieces of CloudFormation template. The only thing you cannot do is look at the value and make decisions based on the actual bucket name, because the bucket name will only be known later.
Conclusion
AWS CDK framework is a very powerful tool for managing your infrastructure in AWS. What used to be physical cabling in data centers is now code in your favorite IDE. Every infrastructure person now becomes developer.
AWS CDK is being heavily developed by both AWS engineers and open source contributors. There are some rough edges and important topics to be aware of, but in general it is the tool of choice for anyone who is developing in AWS.
