


At 1way2cloud we are using cloud native services on Amazon cloud (AWS) to deliver customer solutions with built-in preventive security controls. Our solutions have often been pentested without any critical findings.
Many of our customers are from the health sector and quite often we are met with their major business requirement: “It should not be possible for any operator (company employees, 1way2cloud developers, AWS service operators) to see customer data”.
So, how can we address that?
In this post we will be describing a real production application we developed for one of our customers.
Let’s start with cloud architecture first…
To comply with the data residency requirements, all data is stored and processed in Switzerland (Zurich region).
We are using the Frankfurt region for certain services that are still not available in Zurich but they don’t process or store any data.

This is a standard AWS serverless architecture that we normally use. Application frontend content (React) is served from Amplify service while backend REST API calls are being dispatched through API Gateway. Behind API Gateway is business functionality implemented via a set of Lambda functions. The data is stored in an RDS database and S3 object storage (for images). User authentication is done via Cognito. All the content is exposed through CloudFront CDN, protected by WAF, Shield Advanced and TSL Certificates.
CloudWatch and X-Ray are used for application logging and monitoring. SecurityHub is used as an overall AWS environment monitoring solution that integrates security findings from GuardDuty and Config.
Now, let’s see what possible threats we can have in such cloud setup.
Threat 1: an external attacker intercepting the communication line

Entry door to the application is CloudFront CDN. It is also the only endpoint that we expose to the outside world.
There we have three levels of protection to protect us from the external attackers:
- Web application firewall that is protecting applications from the common web application security attacks (see OWASP for more info)
- Certification manager that provides TLS (Transport Layer Security) encryption to protect data in transit (from client’s web browser to CloudFront)
- Shield Advanced that is protecting the application from DDoS attacks
Since CloudFront is a CDN (Cloud Distribution Network) that is using AWS edge locations to serve content closest to the users, attackers don’t have many hops (DNS servers) to try to intercept the traffic. Distance from the end users and one of the available CDN edge locations is as close as it gets. Once the traffic reaches CloudFront, it is getting onto the internal AWS network where external attackers have little chance of attacking (that is AWS’s part of the Shared Responsibility Model, maintaining security of the cloud).
Threat 2: an external attacker targeting backend API
API Gateway also has a public endpoint that is not advertised or visible to the client’s browser. When the client application is making a backend API call, that request is going through CloudFront where the traffic is directed to the appropriate origin based on path: all URL requests that have /api/* in their path are directed to API gateway.
However, by inspecting public DNS entries an attacker could find the API Gateway URL that is in format:
https :// <random string>.execute-api.<region>.amazonaws.com/<stage>
An attacker could try to access that endpoint directly…

…but the attacker wouldn’t succeed as it is not possible to bypass CloudFront.
We are using 40 character long random generated API Key e.g. 6PirkHOpEy3VFSm58Qosq4lOVsElLqpD1dzjZ7Vl1 to secure the line between CloudFront and API Gateway. Any request that comes to API Gateway without this API Key is automatically rejected. Additionally, the API Key on both CloudFront and API Gateway side is being rotated on a regular basis.
If the attacker continually tries to guess the API Key by using brute force, he will be cut off by AWS.

An attacker could get lucky and “guess” the API Key (would be the luckiest attacker in the history). To add an additional layer of protection we are signing all requests with AWS Signature Version 4 before sending them to API Gateway. The signing process is done inside Lambda@Edge function on CloudFront and API Gateway is set to use IAM Authorization to validate the signature. Lambda@Edge has a role that allows calling API Gateway.

Threat 3: a rogue AWS operator accessing managed services
What can an AWS operator do in our environment? To be clear, here we are not trying to protect ourselves from AWS as a vendor. We are trying to protect ourselves from an accidental exposure of critical customer data to an AWS operator (e.g. database administrator) or to a rogue AWS employee who is trying to do something illegal. This is a highly hypothetical situation since AWS itself has tons of internal technical and organisational controls to prevent such attempts.
An internal attacker could try to look at data in transit, in memory or at rest.
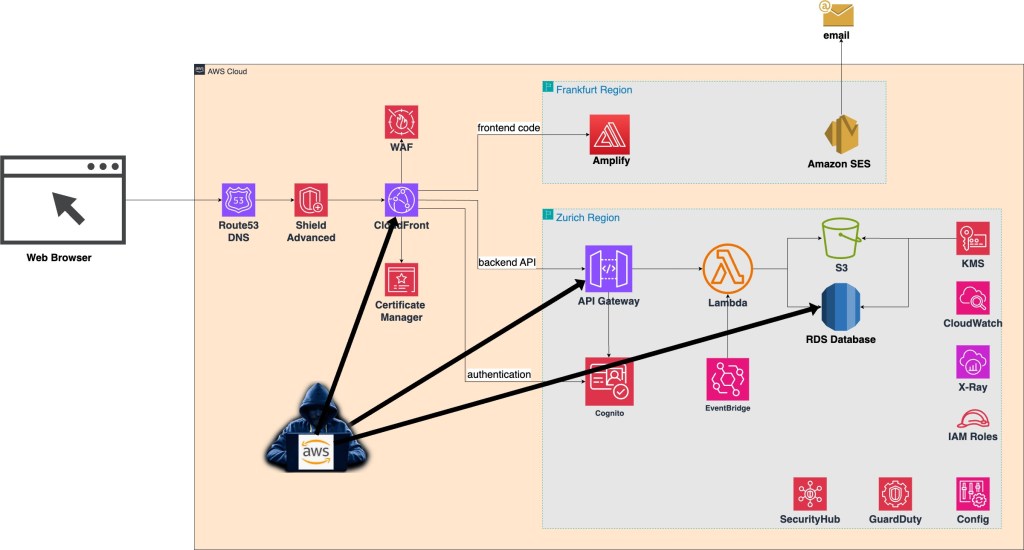
Intercepting data at transit can only happen at CloudFront since that is where TLS connection is getting terminated, payload is being inspected by WAF and then again encrypted when sent back to origins. However, CloudFront is a distributed service across over 450 edge locations around the world. It would be hard for an attacker to compromise some of those 450 locations without being detected by AWS security.
Next point of attack could be data in memory. Requests coming to API Gateway are terminating TLS connection that was initiated by CloudFront and data in API Gateway memory stay unencrypted for a short period of time before they are delivered to destinations, in our case to Lambda.
A rogue AWS operator of API Gateway could see that data. But, he would see garbage. All critical data is encrypted on CloudFront using field level encryption.
Field-level encryption enables secure upload of sensitive information. The sensitive information provided by users is encrypted at the edge, close to the user, and remains encrypted throughout the entire application stack. This encryption ensures that only applications that need the data, and have the credentials to decrypt it, are able to do so. To use field-level encryption, we configure CloudFront distribution so that we specify the set of fields in POST requests that we want to be encrypted, and the public key to use to encrypt them.

CloudFront field-level encryption uses asymmetric encryption, also known as public key encryption. We provide a public key to CloudFront, and all sensitive data that we specify are encrypted automatically. The key we provide to CloudFront cannot be used to decrypt the encrypted values, only our private key can do that. So, an operator cannot see data on CloudFront edge locations even if he manages to get access to those locations.
Decryption of this data is happening inside the Lambda function that is receiving the request.
Attacking Lambda execution environments would be quite difficult due to the distributed nature of Lambda services. Lambda is running on a pool of short lived EC2 instances. You wouldn’t be able to identify a single Lambda execution host and assume it is going to be the same host for all subsequent requests.
Finally, data at rest in the RDS database and on S3 storage. Here we use double encryption:
- Client side encryption using Encryption SDK is used to encrypt data inside Lambda function before sending data to RDS/S3. Important note here is that access to KMS is allowed only to the Lambda IAM role, so that access to encryption/decryption data keys can only happen from within the Lambda application code.
- Customer managed KMS keys are used to encrypt databases on a file level and S3 on an object level. These keys are being automatically rotated by KMS on a regular basis.

Threat 4: a developer accessing production environment
Developers should never have access to the production environment. Only automated deployment tools should have enough access rights to deploy code and instantiate new resources.
The following picture shows our usual development setup that has over years proven to be secure enough.

Developers are pushing code to the GitLab SaaS source code repository. A set of webhooks are configured to trigger Atlantis Terraform deployment tools once a new code is pushed to GitLab. To make sure that only GitLab is allowed to trigger Atlantis we use WAF to whitelist GitLab’s URL and block everything else.
Using predefined IAM roles for cross-account access Atlantis gets enough privileges to deploy new Terraform resources in DEV, SIT and PROD environments.
Developers can still access AWS Console but only DEV and SIT environments with different access rights. Their access is protected with a password and MFA (Multi Factor Authentication) device.
A developer can not be accidentally exposed to production data in any way.
To further monitor activity of each developer, we use IAM Access Analyzer and CloudTrail to see who has been doing what in AWS environments.
Threat 5: a rogue developer
How about a rogue developer who has bad intentions and wants to extract customer data?
There are only a few options how that a rogue developer can try to do:
- Sending data outside the Zurich region
By doing so, we would be violating data residency requirements and would be liable for any damages coming from that.
To prevent this possibility, we are using Service Control Policy on the management account level (where developers don’t have access) to block any region that is not Zurich for data processing and storing of data. - Modifying KMS resource policy
As mentioned earlier, only Lambda can access KMS service to encrypt/decrypt data. We achieve that by setting KMS resource policy to allow kms:Encrypt and kms:Decrypt actions to Lambda IAM role only. A rogue developer could try to modify that KMS policy to allow other users or roles to get access to encryption and decryption actions. We prevent that by using the IAM permission boundary where we limit permission that developers have so it is not possible for them to modify other policies. - Modifying Lambda code
A code that the developer is working on is never deployed directly. There is a GitFlow process that is implemented on GitLab. Each time a developer makes a merge request there is an approval for that code needed by the other developer. Additionally, before Atlantis performs deployment to an AWS environment, another approval is needed. A single rogue developer wouldn’t be able to make a damage. - Sending sensitive data to logs
A rogue developer could try to send sensitive data to CloudWatch logs and expose data through that way. We block that by using log masking of sensitive data in CloudWatch.
Threat 6: hijacking Account Owner access
A real damage can be done if someone takes control over the AWS management account (root level account). In that case, there are no limits to what can be done.
Even the whole AWS account can be closed and all data wiped out.
To prevent that, we use split password and MFA for a master root account that is distributed among three persons (CEO, CTO, CIO). Two people have one part of the password (about 20 characters) and a third person has an MFA device. All three need to come together to be able to login to the management account.
What can we improve further?
One area where we have no control of is the GitLab SaaS application where the source code is stored. We rely on their internal security controls to keep our code safe.
- We could go a step further and use a self-hosted GitLab solution where we would operate GitLab on a set of EC2 instances inside our AWS environment.
- We could also use external code analysis solutions such as Snyk to find any potential vulnerabilities in our code before we deploy it.
- The Code that is used in Lambda can be digitally signed so we know it is unaltered. AWS Signer is a good solution to be used here.

Conclusion
In this post we showed technical controls that are protecting our cloud environment from possible external and internal threats made by a single rogue person. We are not providing protection from phishing/impersonating attacks at the end-user side or a joint illegal action by a group of developers for example. Technical controls always need to be accompanied with organisational controls that are making sure processes exist and are followed to prevent excessive and long running access rights to individuals or groups of people.
There is no perfectly secure and impenetrable system. As long as systems are being developed and maintained by humans, there will always be a way to get access to those systems.
Artificial Intelligence might change that one day but for AI to be able to create a perfectly secure system, it needs to use perfectly secure foundations. Currently, those foundations (cloud services, commercial and open-source libraries, SaaS tools etc.) are imperfect, often buggy and generally unreliable. Only humans with lots of previous experience (if in need for such experience, contact 1way2cloud 🙂 ) working with those tools can tweak such an imperfect ecosystem into a functioning application that works most of the time and is relatively secure.
Until then, we can use the security measures mentioned in this post to defend us from the majority of threats out there. For most businesses today, that is secure enough.
